Responding to "the Internet is disintegrating"
The following post is my opinion on an article I've recently read and the issues it raises.
This isn't really my typical sort of post, but after I read this article on BBC Future recently I felt I had to post to set a few things straight.
The article talks about how authoritarian governments are increasingly controlling Internet traffic that's flowing through their countries. This part is true - China has their "great firewall", and several countries have controversial "off-switches" that they occasionally flip.
Internet protocols specify how all information must be addressed by your computer, in order to be transmitted and routed across the global wires; it’s a bit like how a Windows machine knows it can’t boot up an Apple operating system.
This is where it starts to derail. While Internet protocols such as HTTP and DNS do specify how different machines should talk to each other, it bears no resemblance to how a computer boots into it's operating system. In fact, it's perfectly possible to boot into macOS on a PC running Windows. It's important to distinguish between the hardware and the software running on it.
It also talks about "digital decider countries" being "scared" of an "open Internet".
“Nations like Zimbabwe and Djibouti, and Uganda, they don’t want to join an internet that’s just a gateway for Google and Facebook” to colonise their digital spaces, she says. Neither do these countries want to welcome this “openness” offered by the Western internet only to see their governments undermined by espionage.
Again, with this theme of not distinguishing between the hardware or network, and the software that's running on it.
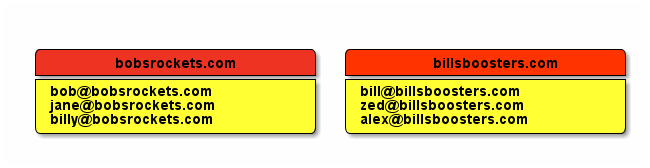
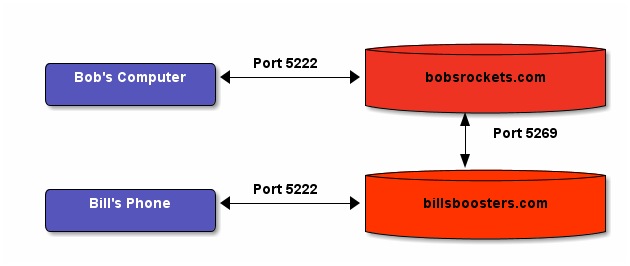
An open Internet is not a space in which the likes of Facebook and Google hold total control. An open Internet is one in which people like you and me have choice. Choice of social network. Choice of email provider. Choice of news outlet.
An open Internet is defined by the choices we, as consumers, make. If everyone decides to use Facebook, then the Internet will then be subsequently dominated by Facebook. However, decentralised options do exist (also this) - and are increasing in popularity. Under a decentralised system, no 1 company has control over everyone's data, how it's processed, and who sees what.
While the obvious solution here is to simply 'block' misinformation and illegal content, it's not an easy one to implement, and it certainly comes with serious moral and ethical implications. How do we decide what is 'illegal' and what is 'legal'? How do we tell if a news article is 'real', or 'fake'? With over 10 million requests / second to CloudFlare alone, that's certainly far too much data flying around the Internet to handle manually.
Let's say we built an AI to detect what was legitimate, or implemented a set of rules (say, like a blacklist). What about satire? How do you decide out of the 1.3 billion web servers (not to mention that a single web server is likely to host several websites) which is legitimate, without potentially damaging vital competition to bigger businesses?
No algorithm is going to ever be 100% accurate. With this in mind, utilising such an algorithm would carry the terrible cost of limiting freedom of speech and communication. How can a government, which to my understanding is there to serve and represent the people, in good faith control and limit the freedom of expression of the people it is supposed to represent? There's a huge scope for abuse here, as has been clearly demonstrated by multiple countries around the world.
If blocking doesn't work, then how can we deal with misinformation online? Well, Mozilla seems to have some ideas. The solution is a collective effort: Everything from cross-verification of facts to linking to sources. When writing an article, it's imperative to link to appropriate sources to back up what you're saying. Cross-checking something you read in 1 article with another on a different website helps to ensure you have more sides of the story.
Although governments may claim that internet sovereignty protects its citizens from malware, many fear losing the freedom of the "open internet"
Malware is indeed another serious problem. Again the solution here is not "blocking" content, as malware authors will always find another way (also exhibits b, and c) to deliver their payload.
Again, the solution is in the hands of the people. Keeping systems up-to-date and making use of good password practices all help. Ensuring that device, networks, and software are all secure-by-design is great too (the website I was reading the article on doesn't even implement HTTPS correctly).
The article feels very one-sided. It makes no mention of the other alternative ways I've touched on above, or those tackling the challenges the article talks about in ways that don't harm freedom of expression. In fact, I'd say that it's more of an opinion piece (much like this post), but since it doesn't mention that it is as such, I feel it's rather deceptive.
...one thing is clear – the open internet that its early creators dreamed of is already gone.
Indeed, the early vision of the Internet has changed drastically as it's grown. However, your personal data belongs to you, so you've got the power to choose who processes it.
Sources and Further Reading

 Mailing List
Mailing List
 Articles Atom Feed
Articles Atom Feed
 Comments Atom Feed
Comments Atom Feed
 Twitter
Twitter
 Reddit
Reddit
 Facebook
Facebook