
 Mailing List
Mailing List
 Articles Atom Feed
Articles Atom Feed
 Comments Atom Feed
Comments Atom Feed
 Twitter
Twitter
 Reddit
Reddit
 Facebook
Facebook
Jabber & XMPP: A Lost Protocol
Welcome to a special tutorial post here at starbeamrainbowlabs.com. In this post, we will be exploring an instant messaging protocol known as XMPP.

Today, you will probably use something like Skype, Gmail, or possibly FaceTime to stay in touch with your friends and family. If you were to rewind to roughly the year 2000, however, you would find that none of the above existed yet. Instead, there was something called XMPP. Originally called Jabber, XMPP is an open decentralised communications protocol (that Gmail's instant messaging service uses behind the scenes!) that allows you to stay in touch with people over the internet.
Identifying Users
There are several programs and apps that have XMPP support built in, but first let's take a look how it works. As I mentioned above, XMPP is decentralised. This means that there is no central point at which you can get an account - in fact you can create your very XMPP server right now! I will go into the details of that in a future post. Having multiple servers also raises the question of identification. How do you identify all these XMPP users at hundreds, possibly thousands of server across the globe?
Thankfully, the answer is really quite simple: We use something called a Jabber ID (JID), which looks rather like an email address, for example: [email protected]. Just like an email address, the user name comes before the @ sign, and the server name comes after the @ sign.
Connecting People
Now that we know how you identify an XMPP user, we can look at how users connect and talk to each other, even if they have accounts at different servers. Connecting users is accomplished by 2 types of connections: client to server (c2s) and server to server (s2s) connections, which are usually carried out on ports 5222 and 5269 respectively. The client to server connections connect a user to their server that they registered with originally, and the server to server connections connect the user's server to the server that hosts the account to the other user that they want to talk to. In this way an XMPP user may start a conversation with any other XMPP user at any other server!
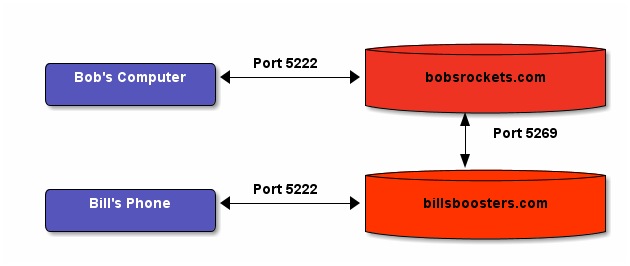
Here's an example. Bob is the owner of a company called Bob's Rockets and has the XMPP account [email protected]. He wants to talk to Bill, who owns the prestigious company Bill's Boosters who has the JID [email protected]. Bob will log into his XMPP account at bobsrockets.com over port 5222 (unless he is behind a firewall, but we will cover that later). Bill will log into his account at billsboosters.com over the same port. When Bob starts a chat with Bill, the server at bobsrockets.com will automagically establish a new server to server connection with billsboosters.com in order to exchange messages.
Note: When starting a conversation with another user that you haven't talked to before, XMPP requires that both parties give permission to talk to one another. Depending on your client, you may see a box or notification appear somewhere, which you have to accept.
Get your own!
Now that we have taken a look at how it works, you probably want your own account. Getting one is simple: Just go to a site like jabber.org and sign up. If you stick around for the second post in this series though I will be showing you how to set up your very own XMPP server (with encryption).
As for a program or app you can use on your computer and / or your phone, I recommend Pidgin for computers and Xabber for Android phones.
Next time, I will be showing you how to set up your own XMPP server using Prosody. I will also be showing you a few of the add-ons you can plug in to add support for things like multi-user chatrooms (optionally with passwords), file transfer proxies, firewall-busting BOSH proxies, and more!